Goal:
Replace the previous ABM ie Annual Bibliometric Monitoring / Årlig Bibliometrisk Uppföljning at KTH
Our previous demo meeting was held 2019-12-05.
Since then (> 3 months ago) we have worked on Sprints 8 to 11 (current)
2020-03-24
Goal:
Replace the previous ABM ie Annual Bibliometric Monitoring / Årlig Bibliometrisk Uppföljning at KTH
Our previous demo meeting was held 2019-12-05.
Since then (> 3 months ago) we have worked on Sprints 8 to 11 (current)
The 1.0 release is done, three releases have been published so far
Progress - What is new since last meeting?
A short demo of the ABM app
Future directions after 1.0 release
Our questions to you
Your feedback and your suggestions and comments to us
The first step of the project plan was a re-implementation of the old ABM.
There is now a public version of the app showing breakdowns for KTH units. It allows researchers to login using their KTH account to view their own data.
Demo of Dashboard / Shiny App


The number of publications for the row with least number of publication in each table.
A warning text if any row is based on less than 50 publications.
Shows the Web of Science coverage for the row with least coverage in each table.
Displays poor, moderate or good WoS coverage.
For individuals, there is a general word of caution for everybody regardless of size or coverage.
Going forward, we have planned to work on these areas:
Please think about what would be most interesting to you in the short run?
Currently:
More information needed, such as:

Feel free to look at these resources if you are interested in the our workflows and potential applications (beyond the ABM 1.0 app) in the future.
kthapi for accessing data from KTH APIsdblp for accessing data from API at https://dblp.org (CS biliographics)XsearchLIBRIS for searches against LIBRIS and SwePubktheme … used for example to make these slidesn help?Open source-based platform for reproducible research including web-friendly data analysis:
Front-end for open data science KONTARION
Can do ML och AI, scales locally or in the cloud using Docker Swarm / Kubernetes, container-based, supports ML/AI workflows using R, Python (Jupyter) etc… GPU-scaling and slurm jobs)
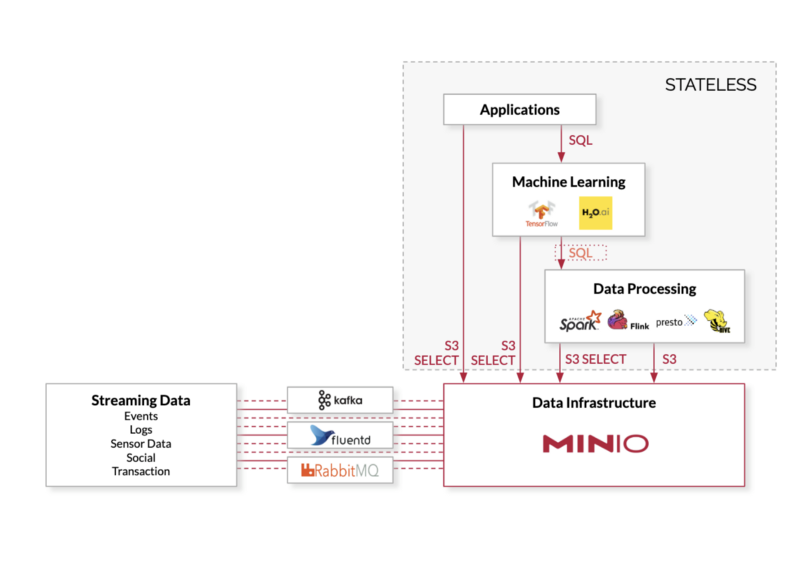
Add-on: Backend for big data using Apache Spark + Minio + Select S3
![]()
Data Lake w/ Minio + Apache Spark + S3 Select + RStudio Web Edition / JupyterHub

{kind=link}